
星期天上班,編輯跟我說,昨天整理長榮罷工受影響的航班資訊花了一下時間,雖然也沒什麼,但是如果遇到幾百班的時候手工就很OOXX……有了上次華航罷工的經驗,我這次挑戰自己一個小時內做完:python爬蟲+spreadsheet串連(雖然我也不確定這表格能幫到多少讀者…)
python code
這次用到的包:
import requests
import pandas as pd
import datetime
import time as tm
import gspread
from oauth2client.service_account import ServiceAccountCredentialsgspread應該不多人用,當時找文章還找挺久的,不過當年看了這篇翼之都的文章,搭配官方文件,模仿著用,倒也是用了一兩年這麼久。
找到長榮罷工取消航班的頁面,現在看來如果用這些參數可能可依條件得到比較乾淨的資料。當下沒想太多就requests讀這個網頁,接著用pandas把網頁表格化成dataframe:
url = "https://booking.evaair.com/flyeva/EVA/B2C/flight-status-erc.aspx?lang=zh-tw&cmstitle=erc-note9&date=20190621-20190630&airport=TPE/TSA/RMQ/KHH&Orderby=&reqtime=&ACTCODE=&REASON=#"res = requests.get(url).text
df = pd.read_html(res)
因為網頁裡有很多個表格,因此上一步拿到的df是list,用迴圈把它兜成一張大表、重新命名欄位,並透過篩選清理,確保狀態都是「取消」的航班。
df1 = pd.DataFrame()
for i in df:
df1 = df1.append(i)df1.columns = ['班機編號','出發地','目的地','表定','最新動態','航班狀態','備註']
df2 = df1.query('表定 != "表定" & 航班狀態 == "取消"').copy()
這樣就爬好了,它…真的…是爬蟲嗎?接著要把它寫進Google Spreadsheet裡,這段就是用Google API取得試算表權限。
def auth_gss_client(path, scopes):
credentials = ServiceAccountCredentials.from_json_keyfile_name(path, scopes)
return gspread.authorize(credentials)auth_json_path = ' #自己的json 'gss_scopes = ['https://spreadsheets.google.com/feeds']
gss_client = auth_gss_client(auth_json_path, gss_scopes)
設定要把資料寫到哪裡:
file = gss_client.open_by_key(' #試算表的id ')
worksheet = file.worksheet("raw") #分頁名稱#把資料寫進表格field = [df2['班機編號'], df2['出發地'], df2['目的地'], df2['表定'], df2['最新動態'], df2['航班狀態'],df2['備註']]
column = ['A','B','C', 'D', 'E', 'F', 'G']
for x, y in zip(field, column):
cell_list = worksheet.range('{}2:{}{}'.format(y, y, len(x)+1))
for r, cell in zip(x, cell_list):
cell.value = r
worksheet.update_cells(cell_list)
tm.sleep(1)
紀錄一下更新時間,也寫進Spreadsheet:
ts = datetime.datetime.now().strftime("%m/%d %H:%M")
worksheet.update_acell('M1', ts)Spreadsheet formula
寫進來長成這樣:

最麻煩的問題應該還是洗日期時間,從上表可以看到D欄是把出發時間、抵達時間寫成一筆文字資料,不是很容易篩選與排序(說不定硬用A-Z可行,但我沒試)。寫了一段公式處理:
=arrayformula(split(regexreplace(regexreplace(REGEXREPLACE(indirect("D2:D"&counta(D1:D)),"2019年|出發|抵達",""),"月","/"),"日"," ")," -"))- 用regexreplace把「2019年|出發|抵達」這幾個字刪掉
- 用regexreplace把月取代成/、把日取代成空白
- 用split把空白跟-區分成不同欄位
- 用arrayformula把這個公式套用到下面的列
- 用indirect製作列數,這是讓arrayformula跑到沒有資料的列時就會停止,避免回傳#N/A,只是比較乾淨,沒做也不會怎麼樣
就可以得到I、J、K、L欄的資料:
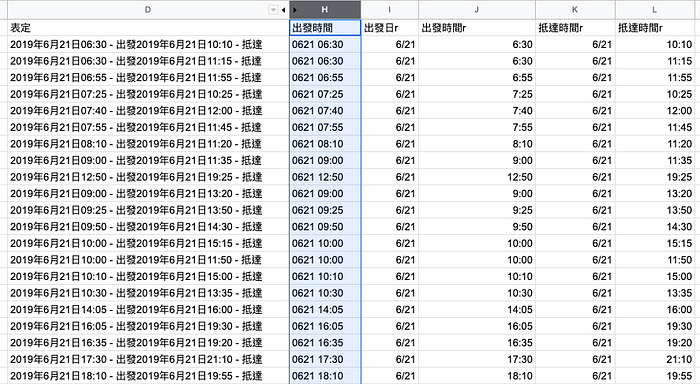
=text(TEXTJOIN(" ",true,I2,J2),"mmdd hh:mm")再組合成H欄的時間,一路套用下去。這樣子就整理完了,成品是下圖,但要怎麼每日自動篩選?
=sort(filter({raw!A2:C,raw!H2:H},raw!I2:I=today()),4,true)- 用filter,先指定位置在{raw!A2:C,raw!H2:H},再設定條件=today()
- 用sort,針對第4欄也就是「出發時間」進行排序,true是順序,false是反序。
這樣子表格就會依日期篩選,如果要做到只看現在之後的取消航班,就是再加個 raw!I2:I > now() 應該就可以成功(但前提是有做上一步文字轉化成日期)
那!要怎麼自動觸發python去抓呢?windows用內建的工作排程器(不是很好用)、mac用cronjob設定就會定時跑了……